Parsing an undocumented file format
- Published on
A year or two ago, I wrote a parser for an undocumented file format as part of a larger project. This was somewhat challenging and I wanted to share my approach because I thought it was a neat idea that worked well.
CUDA binary formats
I needed to write a parser for CUDA binary files. These are GPU executable files generated from compiling CUDA code and are often embedded within other applications.
The detailed format of these files is unfortunately not publicly available.
Thankfully, NVIDIA provides tools like cuobjdump that can parse and display the information they contain.
As an example, we can look at a snippet of the cuobjdump output for a CUDA binary file within PyTorch:
.nv.info._ZN2at6native13reduce_kernelILi512ELi1ENS0_8ReduceOpIN3c107complexIfEENS0_7NormOpsIS5_fEEjfLi4EEEEEvT1_
// snip
<0x3>
Attribute: EIATTR_KPARAM_INFO
Format: EIFMT_SVAL
Value: Index : 0x0 Ordinal : 0x0 Offset : 0x0 Size : 0x418
Pointee's logAlignment : 0x0 Space : 0x0 cbank : 0x1f Parameter Space : CBANK
// snip
<0x8>
Attribute: EIATTR_MAX_THREADS
Format: EIFMT_SVAL
Value: 0x200 0x1 0x1
<0x9>
Attribute: EIATTR_CRS_STACK_SIZE
Format: EIFMT_SVAL
Value: 0x0
The output above shows information about a specific CUDA kernel ("a GPU function") including its parameters and layout in memory.
My goal was to build a library that could directly parse and extract this information from CUDA binary files.
Building a parser
The core insight I had was that if I could reimplement the cuobjdump tool on top of my library, I could then compare the output of my cuobjdump to the output of the real cuobjdump to validate my parser.
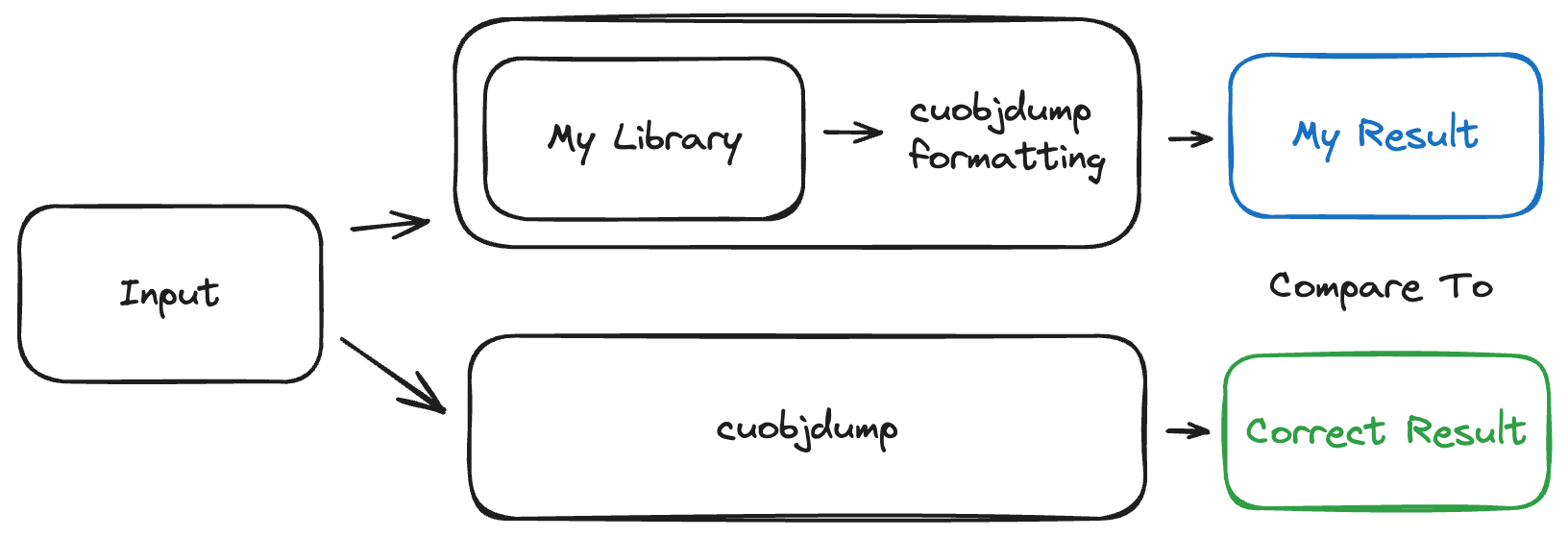
By testing my reimplementation in this way on thousands of CUDA binaries from several major libraries, I could be pretty confident that my parsing library was correct (or correct enough for my needs).
This worked for a few reasons:
- The text output format of
cuobjdumpis relatively clear and straightforward to implement given the output of a parser - We can get several thousand test files. In fact, if we extract all the CUDA binary files in PyTorch, we get ~3830 files!
cuobjdumpcan print out all the information in a CUDA binary (i.e. it can be used to validate a complete parser)
This approach also made it straightforward to incrementally implement the parser. For example, if my implementation only parsed one field, I could modify the comparison step to only validate that piece of the output. This let me check a subset of the parsing logic across thousands of files without needing to understand the whole file format.
By highlighting specific differences between the output of the real cuobjdump and my implementation, it became easy to find and fix bugs. This also made it easy to add support for new versions of CUDA and new GPU architectures.
Concretely, if I was trying to parse a byte sequence like 0x04 0x17 ..., I could look at a bunch of examples and come up with a hypothesis like "If the first byte is 0x04, the format is EIFMT_SVAL." By testing hypotheses like this one across all the sample files, I could build the parser piece by piece. This was fairly efficient because the test process was automated and displayed clear diffs when the outputs didn't match.
Here's the byte sequence that corresponds to the first section of the cuobjdump output above:
0x04 // Format: EIFMT_SVAL
0x17 // Attribute: EIATTR_KPARAM_INFO
0x0c 0x00 // The size of the rest of the section in bytes (12)
0x00 0x00 0x00 0x00 // Index: 0
0x00 0x00 // Ordinal: 0
0x00 0x00 // Offset: 0
0x00 // logAlignment: 0
// space, cbank, parameter space, and size are packed into these three bytes
0xf0 0x61 0x10
Open source
The parser and test suite are now open source at https://github.com/VivekPanyam/cudaparsers. Feel free to check out the repo if you're curious about the details.
Other uses of this technique
This general approach works well when building and testing alternate implementations of things.
The overall idea is that if you have a way of getting the "right" answer for a lot of sample inputs, you can use it to test and incrementally build your own implementation of something.
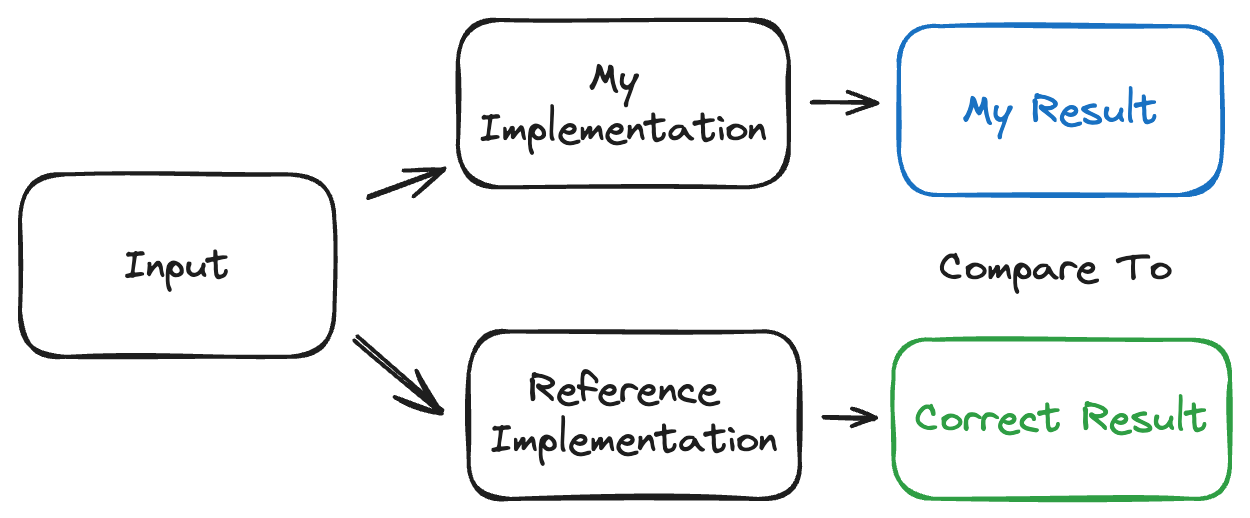
By automating and scaling this process to lots of inputs, you can have high confidence in your implementation. It's especially useful if the output format lets you do fine-grained comparisons that provide useful information about what is incorrect1.
There are probably several examples of this technique in practice, but here's one that comes to mind at the time of writing:
- When implementing Yoga (a flexbox layout engine), the team behind it used a browser as the reference implementation and built a test suite that compared the output of Yoga and the browser
If you have interesting examples of this approach or any other thoughts, feel free to send me an email!
Footnotes
You can take this even further in some cases and replace "my implementation" with a machine learning algorithm. I've previously used this technique to build lightweight ML models that approximate computationally intensive reference algorithms. ↩