Deep Learning Made Simple [Part 1]
- Published on
This series of posts was initially created as a way to explain Neural Networks and Deep Learning to my younger brother. Therefore, we are not going to assume any prior knowledge of calculus or linear algebra, among other things.
Disclaimer: The goal of this post is to be as easy to understand as possible. Because of that, some of the statements below aren't entirely accurate. Many of the larger inaccuracies are marked with *
Contents:
- Deep Learning Made Simple [Part 1] - this post
- Teaching a Neural Network [Part 2] (to be published)
- ...
What can Deep Learning do?
Deep learning is an amazing tool that can generate some very impressive results. Let's look at some of these before we dig into how it actually works.
- Deep learning can turn a photo into a painting of a particular style:
- Or better yet, turn a photo into a photo of a different style:
- It can beat the world's best Go players
- and can beat humans at a bunch of other games:
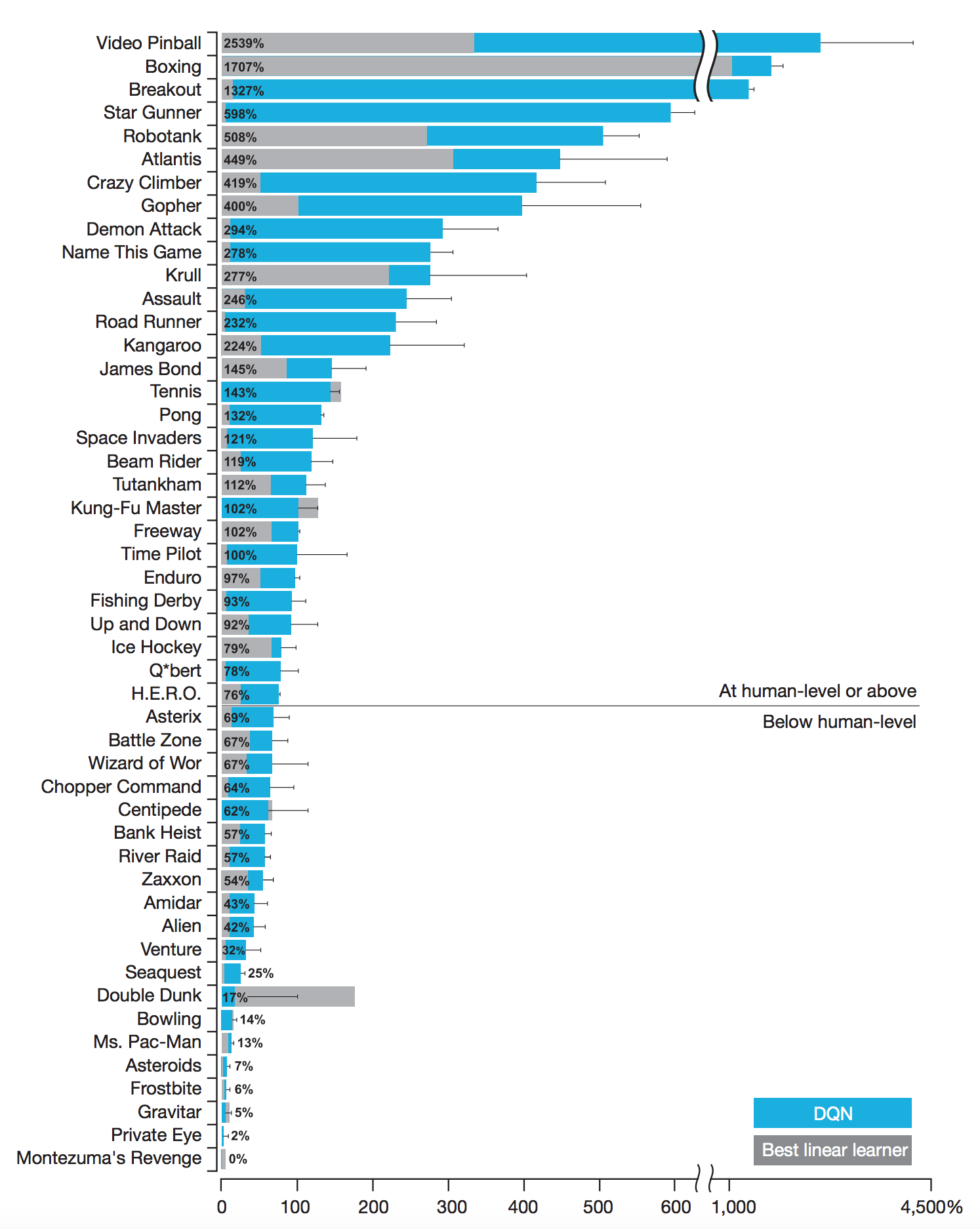
- It can detect and identify objects:

- It can caption images:

- Or even colorize them:

- It can translate between languages
- It can recognize speech
- It can generate voices
- It can turn a drawing into a picture
- It can understand handwriting
And much much more.
... how?
In order to understand that, we need to dig into some basic math first. Let's define what a function is.
The definition we're going to use is as follows (from Wikipedia):
In mathematics, a function is a relation between a set of inputs and a set of permissible outputs with the property that each input is related to exactly one output.
Basically, a function takes in some number of inputs and has an output. Every time the same inputs are passed into a function, it should give us the same output.
Also note that the output of a function doesn't need to be just one number. It can also be a vector.
For our purposes, a vector is an ordered list of numbers
For example if we have a vector :
- is the first element
- is the second element
- ...
Functions can be as complex or as simple as we want. Here are some examples:
items_in_picture = f(image) = ?speaker_identity = f(audio_signal) = ?
In the above list, think of ? as "something super complicated that we don't know how to write down."
At first glance, the last two items in the list of examples might look weird, but if you look carefully, they fit all our rules for functions:
- They relate inputs and outputs.
- For a given input, they always have the same output.
Now that we know what a function is, let's define what the purpose of deep learning is.
The end goal of most machine learning methods, including deep learning, is to figure out how to write down complex functions. In more concrete terms, machine learning methods try to estimate a function.
So how can we estimate a function we don't know how to write down? Let's look at this problem a slightly different way.
Estimating a function
Let's pretend someone told us that there's a function that does something interesting and they asked us to figure out what is. Since they're feeling particularly generous, they'll also give us a bunch of examples of corresponding and values.
In mathematical terms, they asked us to come up with a function such that for all possible values.
So how do we know if we're doing a good job? We need some way to tell how close is to .
Let's use the distance formula that we learned in middle school (actually called the Euclidean Distance or L2 Norm). We'll call this where and are two vectors.
Great! So if we minimize for all points , we should come up with the correct .
One slight hiccup; we don't know what looks like and can be "something super complicated that we don't know how to write down". How can we minimize distance if we can't write it down?
We'll tackle these problems over the next two sections.
Taking inspiration from nature
This seems like a good time to look at the human brain. Our brain is made of 86 billion neurons. A very simple diagram of a neuron is below.
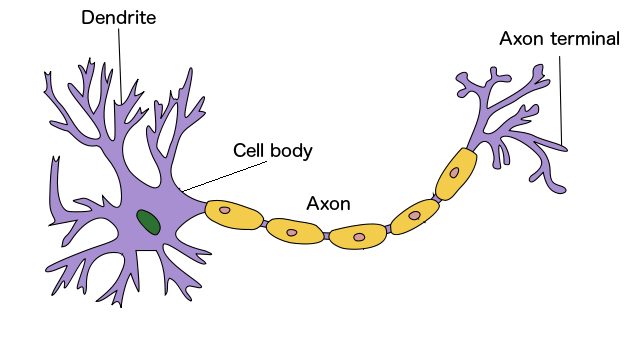
The basic way a neuron works is as follows:
- Dendrites take signals from other neurons and send them to the Cell Body.
- The Cell Body takes the input signals, does some processing, and decides to "fire" or not.
- If the neuron is going to "fire," the Axon sends the output to other neurons (using the Axon terminal).
The places where the Axon of one neuron connects to a Dendrite of another neuron is called a Synapse. The human brain has between 100 trillion and 1 quadrillion synapses!
Artificial Neural Networks
Let's take some inspiration from the neurons in our brains and create an artificial neuron. Let's say our neuron takes 3 inputs and has one output:

So that means our neuron is a function that looks like this:
Let's also say that our neuron is a linear function.
A linear function is a function that represents a straight line or plane.
So now we have
(where all the constants can be different)
Now that we've built a neuron, let's put a bunch of these together to build a neural network!
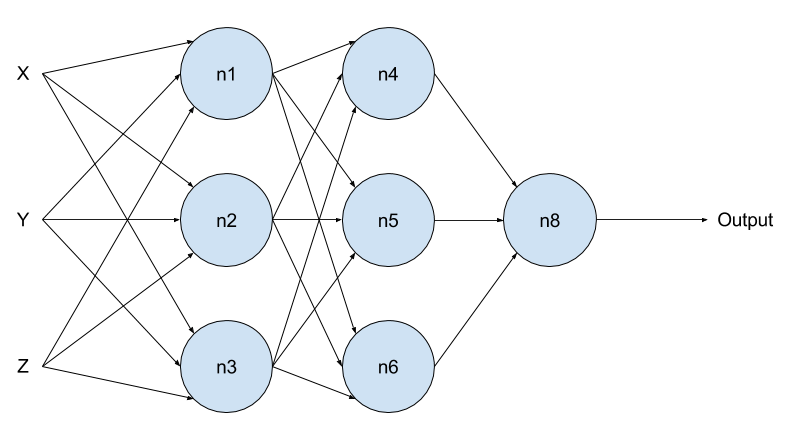
Let's run through the math really quickly to see what actually is.
The output of the final layer of the neural network (n8) is:
The outputs of the second layer of the network (n4, n5, and n6) are:
The outputs of the first layer of the network (n1, n2, and n3) are:
After combining all the equations above, we get:
(again, where can be different every time it's mentioned)
So, that's a problem. Even if we have a super complicated combination of these neurons, it still can't do anything except fit a line or a plane. Why?
A linear combination of linear functions is linear.
Read that a few times and convince yourself it's true. Basically, if all you can do is add and multiply by constants, no matter how many times you do it, you'll still end up with a linear function.
So to make neural networks useful, we need to introduce nonlinearities.
A nonlinearity (or nonlinear function) is a function that does not have a linear relationship between its inputs and output. To keep it simple we'll just call these functions .
Let's change our function for each neuron to include a nonlinearity
We'll dig into this more in the next post, but, for now, nonlinearities solve our problem!
In fact, now that we have nonlinearities, we can show that "for every function, there exists some neural network to represent it".* This means that any function you can come up with can be represented by a neural network!*
The proof, exact wording, and caveats of this statement are out of the scope of this post, but if you want more detail, you can look at the Universal Approximation Theorem.
Since we know is a function and we know that there exists some neural network that can represent any function*, let's make a neural network!
Hot and Cold
Unfortunately, we still don't know how to minimize our distance function. Let's try to figure out how to do that.
Remember the game "Hot and Cold"? You try to find an object and as you move, your friend tells you "hotter" or "colder" depending on whether you're moving towards the target object or not.
The game looks something like this:
- A target object is chosen
- Start somewhere in the center of the room
- Until you find the object:
- You move in a direction
- Your friend yells out "Hot" or "Cold"
- If they yelled out "Cold," move in the opposite direction
What if we played that game to minimize a function? Let's say our "target" is to find the minimum value of our distance function.
To make things easier to write down, let's also say
where is our neural network and is the function we're trying to estimate.
Let's rewrite how "How and Cold" is played:
- A target value is chosen: the minimum value of
- Start with a random value
- Until you can't decrease any more:
- Move in a direction
- Check if is less than it was before
- If increased, move in the opposite direction and check again
How do we know if we can't decrease any more? If we move in both possible directions and increases both times, that means we found the minimum!*
Let's walk through that game on an example distance function.
Our random starting value is -2. So, based on the graph below, .
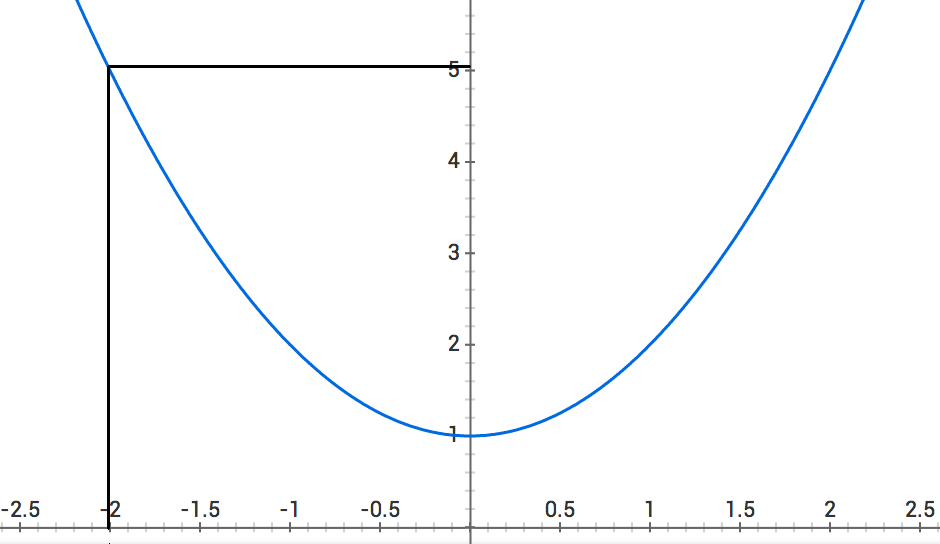
Let's move to and see if is less than it was before.
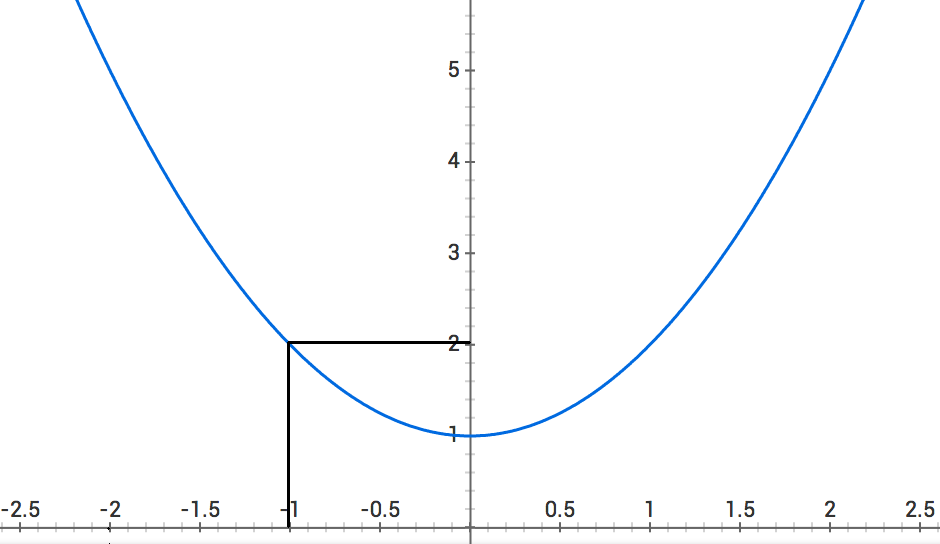
so we're moving in the right direction! Let's move to .
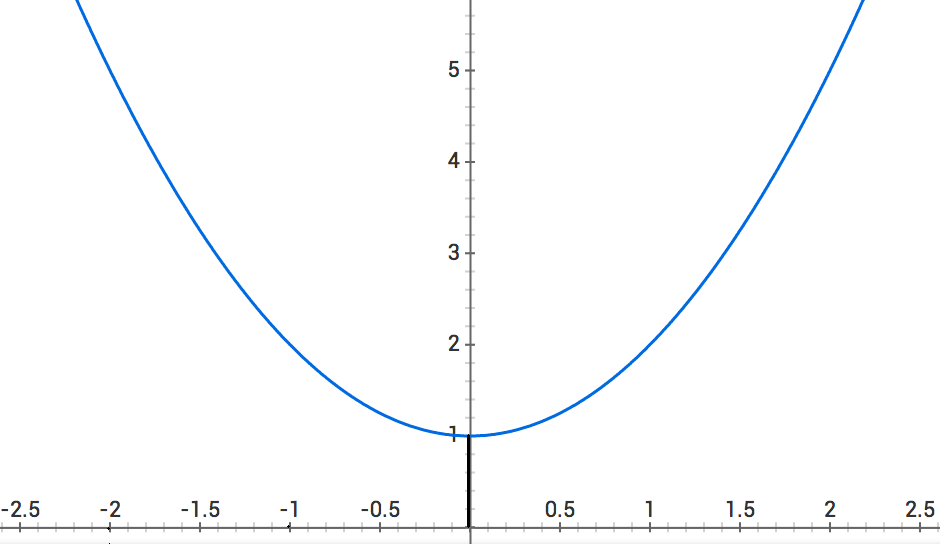
so we're still doing a good job! Let's move to .
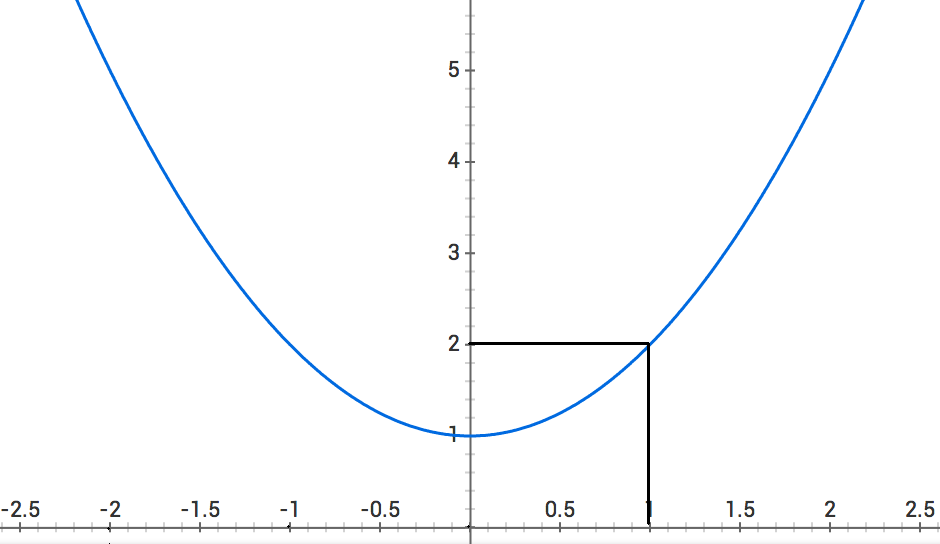
so we're not going in the right direction. Let's do one last check at .
so looks like we found the minimum value at !
Is there a better way to do this? We could have easily overshot the minimum point if we started at a different point or if we chose a different step size. For example, if we started at instead of at , we would have never reached with a step size of (we would have gone from to to ).
Can the slope of a line help us?
The slope of a line between two points and is .
Therefore, the slope of is defined as:
Now let's say that where is some small number. Let's substitute that in:
So if is less than , then otherwise
With this new notation, let's change our game to the following:
- A target value is chosen: the minimum value of
- Start with a random value
- Until you can't decrease any more:
- Subtract from (i.e. )
You'll notice that the last step is the same as this:
- If , we want to increase so we'll subtract from (i.e. )
- Subtracting a negative number from will increase
- If , we want to decrease so we'll subtract from (i.e. )
- Subtracting a positive number from will decrease
Since we do the same thing if or if , I collapsed them down into one case.
This version of the game also has the interesting property that the step size changes depending on the slope. As the slope gets smaller and smaller, our step size gets smaller. That means we slow down as we get closer to our target and we're less likely to overshoot the minimum!
So, now we know how to minimize a function, but the thing is a little weird, right? What if we made really really small? This is called a derivative.
The derivative of a function at a point is the slope of the function at that point.
That's pretty much all you need to know about derivatives for now. Let's look at minimizing a function that is a little more complicated.
Finding the minimum point on a surface
Imagine you're standing on a landscape with a bunch of hills and valleys. It's pitch black outside and you can't see anything. All you know is that you want to get to the bottom of a valley. So what do you do? You feel forward a little bit and see if the surface goes up or down. Then you feel towards the right and see if the surface goes up or down. You keep feeling around and then you finally take a step in the direction that slopes the most downwards.
This is the exact same approach we're going to take.
Let's say that we're trying to minimize some function :
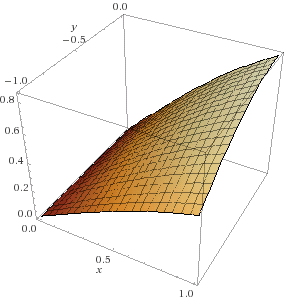
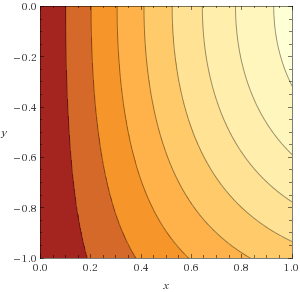
We can't just say though, because there are multiple slopes to measure now. For example, at the point , the slope in the direction (as we decrease ) is steeper than the slope in the direction (as we decrease ).
That's pretty easily solvable. Let's just say "the slope in the direction" or "the slope in the direction" instead of just "the slope". Let's write them down as follows:
- the slope in the direction of =
- the slope in the direction of =
These are called partial derivatives.
Let's also define one more term: the gradient. The gradient of = . Basically the gradient is a vector made up of all the partial derivatives of a function. It has a really useful property:
The gradient of a function points in the direction of the greatest rate of increase of the function
That means the negative of the gradient is the direction that slopes the most downwards. Sound familiar? That's exactly what we were doing in our pitch black landscape example!
So now our game looks like this:
- A target value is chosen: the minimum value of
- Start with a random value and a random value
- Until you can't decrease any more:
- Compute the gradient of
- Subtract from (i.e. )
- Subtract from (i.e. )
This process is called Gradient Descent and it can be used to minimize any function.*
Putting it together
Now that we have a function that can represent any other function*, a measure to see how close we are to correct, and a way to minimize any function*, we've solved the problems that we identified at the beginning of the post!
This also means we can concretely answer the "how" question:
Deep learning uses neural networks with many layers combined with a distance function and a large list of examples to estimate a complicated function.
Let's apply this explanation to the colorization example at the beginning of the post:
- The function we're trying to estimate is
- Since we don't know how to write that function down, we have a large list of corresponding pairs
- Our neural network is some function
- (we'll look into this in more detail in a future post)
- Our distance function looks like this:
Now we can start to put all of these pieces together. Let's substitute and into our function:
Since we don't have , let's use one of our example image pairs instead:
Now we just have to minimize for every example we have!
This presents a problem, however. In our "Hot and Cold" game, we modified an input to in order to minimize it, but we can't modify or in the formula above. Let's rewrite to make it more clear what we need to modify:
We change our neural network.
To minimize , we're just playing the "Hot and Cold" game from above "in the direction"! Remember all the s? We can change all of those to make the network learn!
So we start with a "random" neural network* and then slowly modify the constants until it does a good job on our examples. If we have enough examples and our network learns how to do a good job on them, it should be able to do a good job on inputs it hasn't seen before!*
This process is called training a neural network.
In the next post, we'll look into how exactly we do this. We'll also build a neural network to recognize handwritten digits!
If you want to be notified when I publish the next part, you can follow me on Twitter here.
Please feel free to comment on Hacker News or Reddit or email me if you have any questions!
If you want to learn a little more about me, check out my website or LinkedIn
While you're waiting on part 2, you can also check out my primer on load balancing at scale.
Header image from neural-style on GitHub